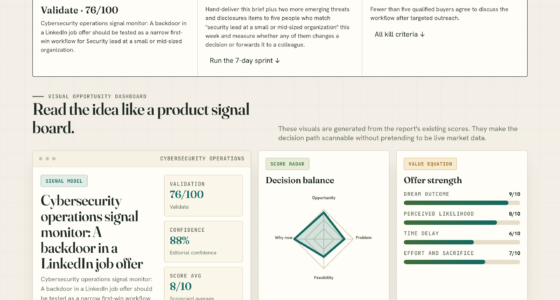
📊 Full opportunity report: Data: The One Thing You Can’t Rent on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
The AI industry is facing a critical chokepoint: data that cannot be rented or freely accessed. As free scraping ends and licensing rises, access to verified, human-made data becomes the key to competitive advantage. This shift impacts startups, incumbents, and the future of AI development.
In 2026, the AI industry has reached a pivotal point: data that was once freely scraped and used is now being fenced, licensed, and protected as a scarce resource. This development marks a fundamental shift in how models are trained and who controls the essential information behind AI systems, making data the new chokepoint in the industry.
Industry experts and legal cases confirm that the era of freely scraping the internet for training data is ending. Notably, Anthropic settled a $1.5 billion copyright dispute in early 2026, establishing that training on legally acquired books qualifies as fair use, but piracy remains prosecutable. This signals a move toward a market-based licensing regime for data, favoring large corporations with the resources to pay high licensing fees.
Meanwhile, the value of high-quality, verified data—such as proprietary expert annotations or domain-specific information—has surged. Companies like Meta have invested billions to secure expert-labeled datasets, making access to rare, human-generated data a strategic advantage. The scarcity of such data is now a decisive factor in model performance and differentiation.
Furthermore, the industry is witnessing a shift in data sources, from open web scraping to exclusive, behind-paywall or confidential data pools. This trend is reinforced by legal rulings and licensing agreements that restrict free access, creating barriers for startups and smaller players who cannot afford the high costs of proprietary data.
Data: The One Thing You Can’t Rent
The free part of “all human knowledge” is running out. As compute and models commoditize, the corpus you can’t replicate becomes the moat — so data is being fenced, priced, and, in places, treated as a national asset.
Data was supposed to be the abundant input. It’s the scarce one. It’s also the chokepoint you can actually own — so guard your proprietary data, and don’t hand it to a provider who can become your competitor (the lesson everyone fled Scale to learn). Nations: license it like Ukraine — keep the model, keep the leverage.
Why Data Fencing Reshapes AI Industry Power
This shift fundamentally alters the competitive landscape in AI development. Large incumbents with the financial capacity to license and acquire exclusive data gain a significant advantage, creating barriers for startups and smaller labs. The move toward data fencing and licensing also raises questions about data access, innovation, and the future of open AI research. As data becomes a protected asset, control over high-quality, verified information effectively becomes a new form of industry dominance, impacting the pace and direction of AI progress.

The Remote AI Training and Data Annotation Handbook: A Complete Work Resource Guide for Earning Online Through Microtasking Platforms
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Legal and Industry Changes Driving Data Scarcity
Historically, AI training relied heavily on freely available web data, with companies scraping vast amounts of information at minimal cost. However, legal actions—such as Anthropic’s $1.5 billion settlement over copyright infringement—and ongoing lawsuits from publishers like The New York Times have shifted this paradigm. Courts have drawn clearer boundaries around fair use, especially concerning copyrighted material, prompting a move toward licensing models.
At the same time, the industry’s focus has shifted from quantity to quality. The need for expert-annotated, domain-specific data has increased, especially as models move toward reasoning and specialized tasks. Companies like Meta and Surge are investing billions in acquiring such data, which is often kept behind paywalls or in proprietary pools, further constraining access for smaller players.
This environment creates a landscape where data is no longer a free resource but a guarded commodity, with legal and economic barriers intensifying as the industry matures.
“The $1.5 billion settlement clarifies that training on legally acquired data is fair use, but piracy is increasingly prosecutable, marking a new legal landscape.”
— Legal expert familiar with Anthropic case
verified proprietary data sets for AI
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unclear Impacts on Smaller Innovators
It remains uncertain how smaller startups and open-source projects will adapt to the rising costs and legal barriers associated with data licensing. The extent to which open data initiatives can survive or whether new, alternative data sources will emerge is still developing.
expert labeled datasets for machine learning
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps in Data Access and Industry Regulation
Legal cases and industry negotiations will continue to shape data licensing frameworks. Watch for further court rulings, new licensing agreements, and potential policy interventions aimed at balancing innovation with copyright protections. Industry consolidation may accelerate as access to high-quality data becomes a key barrier to entry.

Artificial Intelligence in Schools: A Guide for Teachers, Administrators, and Technology Leaders
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Why can’t data be rented like compute or power?
Data is inherently unique and often protected by copyright or proprietary rights, making it impossible to simply rent or lease in the same way as compute resources. Its scarcity and legal protections create a chokepoint in AI training.
How does legal action affect the availability of training data?
Legal rulings, such as copyright settlements and court decisions, are increasingly restricting free scraping and making data access contingent on licensing agreements, thus raising costs and barriers for AI developers.
What types of data are now most valuable for AI training?
High-quality, verified, human-generated data—such as expert annotations, proprietary datasets, and domain-specific information—are now the most valuable and scarce resources for effective AI models.
Will open web data still be useful in the future?
Open web data remains useful but is increasingly supplemented or replaced by licensed and proprietary datasets. The trend suggests a shift toward more controlled and expensive data sources.
What does this mean for AI innovation and startups?
Rising data costs and legal barriers may limit opportunities for smaller players, favoring large incumbents with resources to license exclusive data, potentially slowing innovation from smaller labs and open projects.
Source: ThorstenMeyerAI.com