📊 Full opportunity report: The Continual Learning Research Map: Where the Memento Constraint Stands in May 2026 on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
The research community confirms the Memento Constraint remains a key bottleneck for autonomous AI. Multiple architectural approaches are in development, but no solution is ready for production. The first reliable models are expected around 2028-2030.
Research on the Memento Constraint in continual learning confirms it remains a significant bottleneck for developing autonomous, agentic AI systems. As of May 2026, no method has achieved a production-ready solution, with experts estimating reliable deployment will not occur before 2028-2030.
The Memento Constraint refers to the challenge of enabling AI models to learn continuously from new data without catastrophic forgetting of prior knowledge. This issue has been mechanistically understood since 1989, with modern frontier models exhibiting performance degradation of 40-80% on prior tasks after fine-tuning, depending on the method used. Despite multiple research directions—such as in-weight learning, external memory, post-training reinforcement learning, and architectural innovations—none have produced a fully reliable, scalable solution for large models.
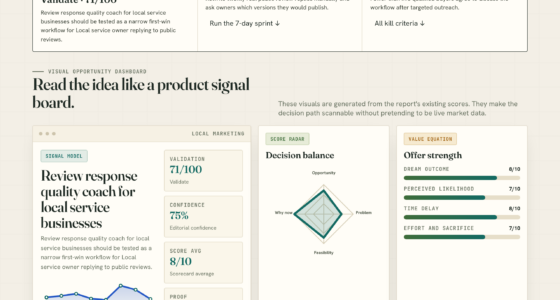
Currently, five main research categories are progressing in parallel: in-weight learning techniques like Elastic Weight Consolidation (EWC) and Synaptic Intelligence (SI), external memory approaches such as ALMA and Evo-Memory, post-training mitigation methods including reinforcement learning and constitutional AI, architectural innovations like mixture-of-experts hybrid models, and hybrid structures involving sparse activations. Each approach addresses different facets of the problem, but none alone suffices. The consensus is that next-generation models—like Opus 5, GPT-6, and Gemini 3.5 Pro—will likely combine multiple techniques to approximate continual learning, but genuine, fully autonomous continual learning remains years away.
Five categories. One bottleneck.
Where the Memento Constraint stands in May 2026. Mechanism understood. Solution still 2028-2030.
In-weight learning · rehearsal-based · external memory · post-training mitigation · architectural. None solves the problem alone. Combinations are necessary. Sparse memory fine-tuning produced the most promising recent result: 89% forgetting → 11% on the canonical TriviaQA / NaturalQuestions split.
Five categories. Twenty methods. Where the research stands.
Each category addresses a different aspect of the continual learning problem. None is sufficient alone; combinations are necessary. External memory is most production-mature; sparse memory fine-tuning is the most promising emerging result.

Continual and Reinforcement Learning for Edge AI: Framework, Foundation, and Algorithm Design (Synthesis Lectures on Learning, Networks, and Algorithms)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Five tiers. Five timelines.
Honest assessment of when each tier of continual learning capability reaches production deployment. Sholto Douglas-Trenton Bricken framing applies: broken early versions before genuine versions.
Deployed
at scale
Emerging
+ early prod
Emerging
scaling up
First versions
research
Possibly 32-35
+ research

ESP32-S3 AI Smart Speaker Development Board, Dual Microphones, Noise Reduction&Echo Cancellation, RGB Lighting, ESP32 Audio, Support Connect External Displays & Cameras, Support AI Speech Interaction
Adopts ESP32-S3R8 module with Xtensa 32-bit LX7 dual-core processor, up to 240MHz main frequency. Supports 2.4GHz Wi-Fi (802.11…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Different labs. Different strategies.
No lab is dominantly leading on continual learning. Capability is being developed in parallel across multiple research programs. The lab that wins durable CL advantage by 2028-2030 will combine multiple approaches.
The AI capability frontier has bifurcated. On dimensions that scale with parameters and compute, the frontier advances on the 2024-2026 timeline. On dimensions that require architectural breakthrough, the timeline is materially slower.
catastrophic forgetting mitigation tools
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Four assignments. By role.
Continue the multi-approach strategy.
No single category will solve continual learning; combinations are necessary. Sparse memory fine-tuning is the most promising recent in-weight result; integrate with external memory and post-training RL. Publish methodology so the community can reproduce. The lab that ships first credible continual learning at frontier scale captures durable capability advantage.
Treat external memory as approximation, not solution.
Plan for memory pollution to compound over deployment time. Implement memory hygiene (periodic summarization, retrieval-quality monitoring, hierarchical memory) as default operational practice. Do not rely on production agents to “learn” from deployment in any meaningful sense — they cannot, yet. Hierarchical memory is the production hedge against the 2030 timeline.
Submit to FMAI / FAGEN.
Continue work on sparse memory fine-tuning at scale — most promising in-weight direction. Develop consolidated continual learning benchmark suites; current fragmentation slows community progress. Mechanistic understanding (Jan 2026 paper and follow-on work) is the foundation for targeted interventions.
Treat CL as 2028-2030 capability.
First broken versions 2028-2030; reliable production 2030+. Do not factor genuine continual learning into 2026-2027 strategic plans; do factor it into 2028-2030 plans. The lab that ships first will capture meaningful market-share advantage; bet accordingly. The bifurcation between scaled-frontier and continual-frontier capability is the structural fact to absorb.

Hugging Face Transformers for AI Automation : A Practical Guide to AI Automation, Model Fine-Tuning, and Scalable Deployment
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Why Overcoming the Memento Constraint Matters for AI Progress
Resolving the Memento Constraint is critical because it underpins the development of truly autonomous, adaptable AI systems capable of learning from ongoing interactions without forgetting prior knowledge. Progress in this area directly influences the timeline for deploying more capable AI agents, which could revolutionize industries, research, and automation. Currently, Western labs maintain a significant advantage in generalization to unseen tasks, and solving continual learning could extend that lead, impacting global AI competitiveness and strategic advantage.
Current State of Continual Learning Research in 2026
The challenge of catastrophic interference was first identified in 1989 and remains central to AI research. Recent empirical studies demonstrate that existing models suffer severe forgetting—up to 80% performance loss—when fine-tuned on new data. The research community is exploring five primary directions, none of which has yet yielded a fully effective, scalable solution for the largest models. The timeline for reliable, production-quality continual learning models is set for 2028-2030, with early approximations already in limited deployment for smaller models.
Recent advances include sparse memory fine-tuning, external episodic memory systems, and reinforcement learning-based mitigation techniques. These methods are improving, but significant technical hurdles remain, especially at the scale of frontier models with trillion-plus parameters. The ongoing research efforts aim to combine these approaches into hybrid solutions capable of near-human continual learning.
“The Memento Constraint remains the central bottleneck for autonomous AI, with no fully scalable solution in sight as of May 2026.”
— Thorsten Meyer
Unresolved Challenges and Timeline Ambiguities in Continual Learning
Despite steady progress, it remains unclear when a fully reliable, scalable solution for the Memento Constraint will be achieved. Technical hurdles, especially at trillion-parameter scales, continue to slow development. Experts estimate that genuinely autonomous continual learning models will not be available before 2028-2030, but this timeline is subject to change as new breakthroughs emerge or unforeseen obstacles appear.
Next Steps in Continual Learning Research and Deployment
Research will continue to focus on hybrid approaches, combining memory, architectural innovations, and reinforcement learning. Pilot deployments of improved approximation techniques are expected to increase, but fully autonomous, continual learning models remain years away. The community anticipates that by 2028-2030, more mature versions of these models will begin to see limited deployment, with broader application following thereafter.
Key Questions
What is the Memento Constraint in AI?
The Memento Constraint refers to the challenge of enabling AI models to learn continuously from new data without forgetting previous knowledge, avoiding catastrophic interference.
When might we see fully autonomous continual learning models?
Experts currently estimate that reliable, scalable models capable of genuine continual learning will not be available before 2028 to 2030.
What approaches are researchers exploring to overcome this constraint?
Researchers are pursuing methods including in-weight learning techniques like EWC and SI, external memory systems, reinforcement learning-based mitigation, and architectural innovations such as mixture-of-experts models.
Why does solving the Memento Constraint matter for AI development?
Overcoming this constraint is essential for creating AI systems that can learn and adapt over time without forgetting, enabling more autonomous, flexible, and capable AI agents.
Source: ThorstenMeyerAI.com