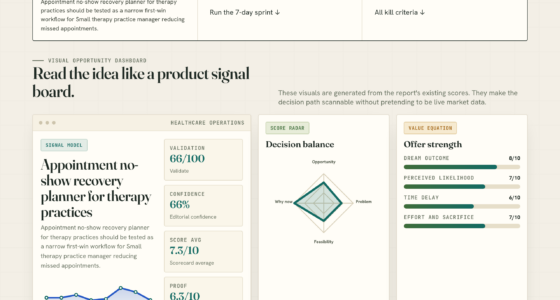

📊 Full opportunity report: Data: The One Thing You Can’t Rent on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
The AI industry’s reliance on freely accessible data is ending as companies secure proprietary, verified data sources. This shift makes data ownership a key competitive advantage, marking a new chokepoint in AI development.
In 2026, industry experts confirm that the era of freely scraping the internet for training data is over, as legal, economic, and strategic barriers are increasingly restricting access to valuable data sources. This shift significantly impacts how AI models are trained and who controls the foundational knowledge for artificial intelligence.
Recent developments include major legal settlements and licensing agreements that mark the end of the open data era. The Frameworks Can’t See the Thing That Matters: A Year of AI-Enabled Cyber Threats Anthropic settled a $1.5 billion copyright dispute by paying for past piracy, signaling a move toward licensed data. Similarly, the ongoing legal case between The New York Times and OpenAI exemplifies the industry’s transition to paid data access. As a result, data that was once freely scraped from the web now commands substantial licensing fees, highlighting the importance of cybersecurity and data protection strategies for AI companies.
Simultaneously, the value of proprietary, verified data has surged. Companies are investing heavily in acquiring or generating unique datasets—such as annotated combat footage or expert-curated information—because synthetic data and algorithms can only go so far without high-quality human input. The industry is increasingly fencing off data behind paywalls, legal restrictions, and strategic partnerships, making data ownership a critical competitive advantage.
Data: The One Thing You Can’t Rent
The free part of “all human knowledge” is running out. As compute and models commoditize, the corpus you can’t replicate becomes the moat — so data is being fenced, priced, and, in places, treated as a national asset.
Data was supposed to be the abundant input. It’s the scarce one. It’s also the chokepoint you can actually own — so guard your proprietary data, and don’t hand it to a provider who can become your competitor (the lesson everyone fled Scale to learn). Nations: license it like Ukraine — keep the model, keep the leverage.
Why Data Ownership Is the New Industry Barrier
This shift matters because it consolidates industry power among large, well-funded firms capable of affording expensive data licenses and proprietary datasets. Smaller startups and newcomers face higher barriers to entry, potentially reducing innovation and competition. The move toward data fencing also raises concerns about data monopolies, privacy, and the future accessibility of high-quality information essential for AI progress.

Understanding Open Source and Free Software Licensing
Used Book in Good Condition
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Legal and Market Changes Reshaping Data Access in AI
Historically, AI training relied on scraping publicly available web data, which was effectively free. However, legal rulings such as Anthropic’s $1.5 billion settlement over copyright infringement have established that scraping copyrighted material without licensing is no longer permissible. This legal precedent, coupled with industry moves toward licensing and paid access, signals a fundamental change. Larger firms are now securing exclusive datasets, and the cost of entry has increased dramatically, favoring established players with deep financial resources.
Additionally, the industry’s shift from simple data labeling to sourcing expert-authored, domain-specific data has increased the value and scarcity of high-quality datasets. Companies like Meta and Surge are investing heavily in acquiring expert knowledge, further intensifying the data chokepoint.
“The $1.5 billion settlement underscores that copyright law is now a decisive factor in AI training data access, setting a clear precedent for future legal standards.”
— Legal expert familiar with Anthropic case

The Remote AI Training and Data Annotation Handbook: A Complete Work Resource Guide for Earning Online Through Microtasking Platforms
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unclear Impact on Innovation and Competition
It remains uncertain how smaller startups will adapt to the rising costs and legal barriers. The long-term effects on innovation, diversity of data sources, and global competitiveness are still developing, with some experts warning that the industry could become more consolidated and less open.
BUISAMG Data Blocker, 4-in-1 Universal USB Data Blocker, Protection from Illegal Downloading, Hacking Proof Guaranteed, for iPhone 17 16 15 and Any USB Device Charging. 2-Pack
✅【4-in-1 Data Blocker】 We have combined the USB-A to USB-C and USB-A to USB-A, USB-C to USB-A, USB-C…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
What Industry Changes Are Expected in 2026 and Beyond
Industry leaders are expected to continue formalizing licensing regimes, leading to increased costs for training data. Smaller firms may focus on synthetic data or niche datasets, while large corporations secure exclusive data assets. Legal and regulatory frameworks around data ownership and copyright are likely to evolve further, shaping the future landscape of AI development.
In the coming months, expect more legal disputes, licensing agreements, and strategic investments in proprietary data sources, reinforcing the trend toward data fencing as the primary bottleneck in AI innovation.
synthetic data generation platforms
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Why is data becoming more valuable than compute in AI?
As models and hardware become more commoditized and cheaper, the unique, verified datasets that underpin high-quality AI models are becoming the primary source of competitive advantage. Data scarcity and ownership now define the industry’s chokepoint.
How does legal action influence data access in AI training?
Legal rulings, such as copyright settlements and court decisions, are establishing that scraping copyrighted material without licensing is illegal. This shifts the industry from open scraping to licensed, paid data access, raising barriers for smaller players.
What types of data are most affected by this shift?
Public web data, such as freely available text and images, are now less accessible due to legal restrictions. Proprietary, verified data—like expert annotations, paywalled content, and specialized datasets—are becoming the new industry standard.
Will synthetic data replace real data entirely?
While synthetic data is increasingly used to supplement real datasets, it cannot fully replace high-quality, verified human-made data, especially in domains requiring expert knowledge. Overreliance on synthetic data risks model inaccuracies and collapse.
Source: ThorstenMeyerAI.com