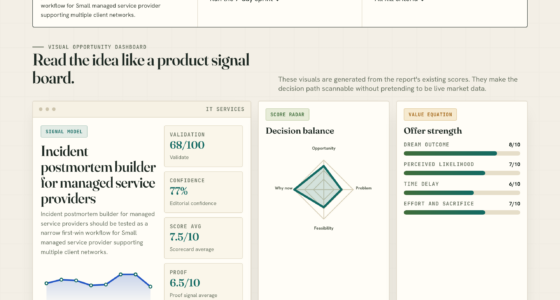
📊 Full opportunity report: The deployment. How the AI labs verticallyintegrated into the serviceslayer — the Palantir modelat scale. on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
In early May 2026, Anthropic and OpenAI announced major moves to embed AI deployment teams directly into client operations, adopting Palantir’s model. This shift aims to capture the large services market but raises questions about scalability and margins.
In early May 2026, Anthropic and OpenAI announced major initiatives to embed AI deployment teams directly into client operations, adopting a model inspired by Palantir’s forward-deployed engineer approach. This move signifies a strategic shift from merely providing models to integrating AI into business workflows, aiming to capture the vast services market and deepen enterprise reliance on their platforms.
Anthropic revealed a $1.5 billion enterprise-services venture involving Blackstone, Hellman & Friedman, and Goldman Sachs to embed Claude AI into mid-market companies. Hours later, OpenAI announced its $4 billion Deployment Company, “DeployCo,” with a valuation of $10 billion, including an immediate acquisition of consulting firm Tomoro to deploy 150 engineers. Both initiatives follow Palantir’s model, where engineers are embedded at client sites to build and operate AI systems directly, rather than just advising or licensing software.
This approach aims to address a key industry insight: while AI models have become commoditized, the real bottleneck in enterprise AI adoption is integrating, securing, and redesigning workflows around these models. MIT research indicates that 95% of generative AI pilots fail to move beyond experimentation, underscoring the importance of deployment and operational integration. The labs’ strategy is to own the deployment process, turning it into a product formation mechanism that generates recurring, token-metered revenue and operational dependency.
The forward-deployed engineer (FDE) model, borrowed from Palantir, involves engineers working closely with clients to develop, deploy, and maintain AI systems, creating switching costs and operational lock-in. This model is both powerful—by embedding operational dependency—and risky—due to its labor-intensive nature, which resembles consulting more than software licensing. The labs are betting that this integration layer will become a scalable product, but whether margins will expand or compress as deployment scales remains uncertain.
The deployment.
How the AI labs vertically
integrated into the services
layer — the Palantir model
at scale.
the identical structural move
the labs had the smaller half
why the embedded customer is rational
the unresolved scalability question
- Blackstone, H&F, Goldman ($300M / $300M / $150M)
- Apollo, General Atlantic, Leonard Green, GIC, Sequoia
- Embed Claude in PE portfolio companies — hundreds of mid-market firms
- Aligned with ~80% enterprise mix
- $10B pre-money · 19 partners (TPG, Bain, Advent, Brookfield)
- Bought Tomoro — 150 FDEs day one (Tesco, Virgin Atlantic, Red Bull)
- Builds the enterprise depth it lacked
- ~2.7x the capital of Anthropic’s vehicle
(the labs sold this)
(the deployment move claims this)
↓
build &
own
The labs have concluded the model is not the product — the deployment is — and moved, in the same week, to own the layer where the model meets the operation. Whether that makes them something larger than software companies or merely rebuilds a labor-bound consulting business at consulting margins is the Palantir question they have all inherited.Thorsten Meyer · The Deployment · Enterprise Reorg 03
Implications of Deepening AI Integration in Enterprises
This shift could redefine how enterprise AI is adopted and monetized. By owning deployment, the labs aim to lock in clients, generate recurring revenue, and move beyond model licensing into operational control. This strategy risks transforming the labs into entities resembling traditional consulting firms, but with a scalable, token-based revenue model. If successful, it could accelerate enterprise AI adoption but also raise concerns about operational dependency and margin compression as deployment efforts scale across diverse clients.

Agentic AI Engineering: Systems That Reason and Act Autonomously – Designing, Building, and Prompting LLM-Based Agents for Real-World Deployment
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Background on AI Labs’ Deployment Strategies
Over the past year, leading AI labs have recognized that model performance is no longer the primary bottleneck in enterprise AI. Instead, deployment, integration, and workflow redesign have become the critical challenges, often stalling projects beyond initial pilots. Palantir pioneered the forward-deployed engineer approach in defense and intelligence sectors, and now AI labs are applying this model to the broader enterprise market. The strategy reflects a broader industry realization: capturing the services dollar—estimated at six times the software spend—is essential for sustained revenue growth.
This move also marks a shift from the traditional software licensing model toward a more embedded, operationally dependent structure. The labs’ adoption of this model signals their intent to become not just providers of AI models but full-stack providers of AI-powered operational systems, akin to what Palantir has achieved in government sectors.
“The labs are adopting Palantir’s forward-deployed engineer model to embed AI directly into client workflows, aiming to capture the large services market and deepen operational lock-in.”
— Thorsten Meyer

The Human-Agent Orchestrator: Leading and Scaling AI-Driven Organizations
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Uncertainties Around Scalability and Margins
It remains unclear whether the labor-intensive FDE model will scale profitably as deployment expands across diverse clients. While the model creates operational dependency and potential for unlimited revenue, it also resembles consulting, which traditionally faces margin pressures. The key question is whether margins will expand as standardization occurs or remain constrained by the high labor costs associated with bespoke deployment efforts.

Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI Deployments
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Milestones in Enterprise AI Deployment
In the coming months, the success of Anthropic’s and OpenAI’s deployment initiatives will be tested by their ability to scale deployment teams, standardize processes, and maintain margins. Industry observers will monitor whether these models evolve into scalable products or remain labor-bound. Further, regulatory and security considerations will influence deployment strategies, especially as operational dependency deepens.

Architecting Data and Machine Learning Platforms: Enable Analytics and AI-Driven Innovation in the Cloud
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
What is the forward-deployed engineer model?
The forward-deployed engineer model involves engineers working directly at client sites to build, deploy, and maintain AI systems, creating operational dependency and ongoing revenue streams.
Why are AI labs adopting this deployment approach?
They aim to address the bottleneck in enterprise AI adoption—workflow integration and operational redesign—and to capture the large services market, generating recurring revenue and lock-in.
What are the risks of this deployment strategy?
The model is labor-intensive and resembles consulting, raising concerns about scalability, margins, and the potential for margin compression as deployment efforts grow.
How does this shift affect the traditional software model?
It shifts focus from licensing models to embedded, operational solutions, making the labs more like full-stack providers and less like pure software vendors.
Will the deployment efforts be profitable long-term?
This depends on whether the labs can standardize deployment processes to reduce labor costs and whether the embedded systems generate sufficient recurring revenue to offset operational expenses.
Source: ThorstenMeyerAI.com